Gdy zadamy modelowi pytanie np. „Czy ta umowa jest ważna według prawa zwyczajowego?”, nie analizuje on przepisów ani orzecznictwa jak człowiek.
Działa jak superzaawansowany autocomplete – przewiduje kolejne słowa na podstawie statystyk z danych, na których został wytrenowany. Proces ten wygląda tak:
- Dzielenie tekstu na kawałki: Najpierw rozbija pytanie na mniejsze fragmenty (tzw. tokeny), np. pojedyncze słowa lub wyrażenia.
- Szukanie wzorców: Sprawdza, jakie słowa i zdania najczęściej pojawiały się w podobnych kontekstach w dokumentach prawnych z jego bazy (np. w umowach, komentarzach, orzeczeniach).
- Generowanie odpowiedzi: Układa płynny tekst, wybierając słowa o najwyższym prawdopodobieństwie. Na przykład, jeśli w danych szkoleniowych zwrot „nieważność umowy” często łączył się z klauzulą o karze umownej, model może zasugerować problem właśnie w tym miejscu – nawet jeśli nie rozumie, dlaczego ta klauzula jest ryzykowna.
Dlaczego to mylące?
LLM potrafi stworzyć tekst, który wygląda na profesjonalną analizę prawną: używa fachowych terminów, cytuje przepisy, a nawet „rozważa” argumenty za i przeciw. W rzeczywistości jednak to tylko iluzja. Model:
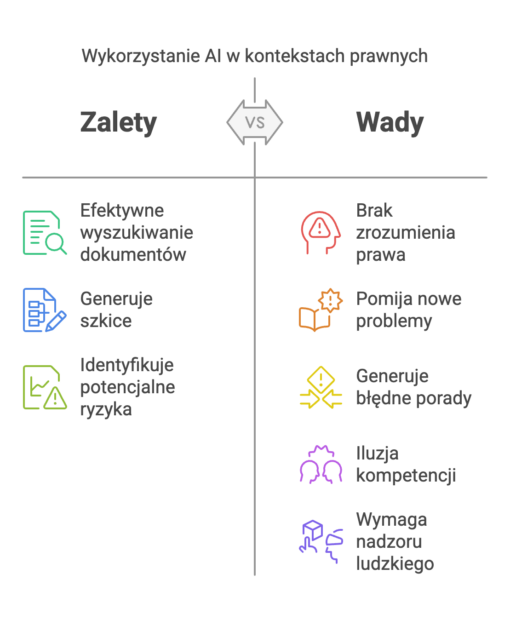
- Nie rozumie logiki prawa – może np. jednocześnie sugerować, że umowa jest ważna i nieważna, jeśli takie sprzeczne przykłady znalazły się w jego danych.
- Omija nowe problemy – jeśli dany wzór (np. specyficzny błąd w umowie) nie występował w treningu, model go nie wychwyci.
- Brak mu kontekstu – nie wie, jakie są realne konsekwencje nieważności umowy lub zmiany przepisów.
Przykład: Przegląd umowy
Gdy model „analizuje” umowę pod kątem błędów, tak naprawdę szuka fragmentów podobnych do tych, które w przeszłości były oznaczane jako problematyczne. Nie rozumie jednak, dlaczego dana klauzula jest ryzykowna – np. nie pojmuje, że ograniczenie odpowiedzialności może naruszać zasadę słuszności.
Ryzyka dla prawników
Nadmierne zaufanie do tych narzędzi może prowadzić do poważnych błędów, np.:
- Przeoczenie nowatorskich problemów prawnych, których nie było w danych treningowych.
- Generowanie błędnych porad w nietypowych sprawach (np. w niszowej jurysdykcji).
- Iluzja kompetencji – elegancko sformułowany tekst może ukrywać brak merytorycznej wartości.
Jak bezpiecznie korzystać z AI w prawie?
Kluczowe jest wykorzystywanie modeli tylko do zadań, w których się sprawdzają:
- Przeszukiwanie ogromnych baz dokumentów w celu znalezienia podobnych przypadków.
- Generowanie wstępnych wersji pism lub standardowych klauzul.
- Podpowiadanie potencjalnych ryzyk (jako wskazówka dla prawnika, a nie zastępstwo jego oceny).
Najważniejsza zasada: LLM to narzędzie wspierające, a nie ekspert. Wymaga stałego nadzoru człowieka – zwłaszcza w dziedzinie tak złożonej jak prawo, gdzie każdy przypadek ma unikalny kontekst.
Oto trzy unikatowe, ale „bezpieczne” (tj. oparte na istniejącej literaturze, z jasnymi ramami badawczymi) tematy na doktorat związane z wyzwaniami AI/LLM w kontekście prawnym:
1. „Etyka generatywnego AI w doradztwie prawnym: Projektowanie ram oceny ryzyka dla modeli językowych w krytycznych zastosowaniach prawnych”
Cel: Opracowanie metodologii identyfikacji i minimalizacji ryzyk związanych z używaniem LLM do analizy umów, sporządzania pism procesowych lub interpretacji przepisów.
Unikalność:
- Połączenie etyki AI, teorii podejmowania decyzji prawnych i inżynierii promptów.
- Analiza przypadków, w których LLM generowały pozornie poprawne, ale sprzeczne z prawem wnioski (np. w prawie podatkowym lub ochronie danych).
Bezpieczeństwo: Bazuje na istniejących pracach z zakresu odpowiedzialności algorytmicznej i compliance (np. regulacje UE dotyczące AI Act).
2. „Hybrydowe systemy człowiek-AI w wykrywaniu luk prawnych: Eksperymentalne porównanie efektywności prawników vs. LLM vs. zespołów mieszanych”
Cel: Badanie, w jakich zadaniach (np. analiza ryzyka w umowach, identyfikacja sprzeczności prawnych) synergia między prawnikami a LLM daje lepsze wyniki niż każda ze stron osobno.
Unikalność:
- Empiryczne testy z udziałem profesjonalistów, z pomiarem zarówno precyzji, jak i „ślepoty kontekstowej” modeli.
- Wprowadzenie metryk jakościowych dla „twórczego myślenia prawnego” w kontekście współpracy z AI.
Bezpieczeństwo: Korzysta z ugruntowanych metodologii z psychologii poznawczej i nauk o zarządzaniu.
3. „Kulturowe zniekształcenia w prawniczych LLM: Jak modele trenowane na zachodnich tekstach prawnych wpływają na interpretację prawa w jurysdykcjach mieszanych (np. RPA, Szkocja, Katar)?”
Cel: Zbadanie, w jaki sposób dominacja anglojęzycznych danych treningowych w LLM prowadzi do niedostatecznej reprezentacji systemów prawnych łączących common law, civil law i prawo zwyczajowe.
Unikalność:
- Analiza konkretnych błędów systemów (np. błędna interpretacja zasad Ubuntu w afrykańskim prawie konstytucyjnym).
- Projektowanie mechanizmów „lokalnego dostrajania” modeli dla wielokulturowych kontekstów prawnych.
Bezpieczeństwo: Wpisuje się w debatę o dekolonizacji AI i różnicach kulturowych w technologii.
Dlaczego te tematy są „bezpieczne” ale unikalne?
– Mają solidne podstawy teoretyczne (filozofia prawa, socjologia technologii, teoria decyzji), ale aplikują je do niszowego kontekstu LLM.
– Łączą metodologie z różnych dyscyplin (informatyka + prawo porównawcze + antropologia), co zmniejsza ryzyko „powielania” istniejących prac.
– Pozwalają na badania empiryczne zamiast czystej teorii, co ułatwia obronę praktycznej wartości doktoratu.
Jak działają modele AI w prawie? by www.doktoraty.plArmour, J., & Sako, M. (2020). AI-enabled business models in legal services: from traditional law firms to next-generation law companies?. Journal of Professions and Organization. https://doi.org/10.2139/SSRN.3418810.
Ansari, T., Dhillon, H., & Singh, M. (2024). Machine Learning Model to Predict Results of Law Cases. 2024 Fourth International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), 1-8. https://doi.org/10.1109/ICAECT60202.2024.10468789.
Ejjami, R. (2024). AI-driven Justice: Evaluating the Impact of Artificial Intelligence on Legal Systems. International Journal For Multidisciplinary Research. https://doi.org/10.36948/ijfmr.2024.v06i03.23969.
Jiang, K., Dai, R., & Wang, F. (2024). Prediction and Analysis of Judicial Small Data Based on Mechanism Model and System Identification. 2024 43rd Chinese Control Conference (CCC), 1476-1482. https://doi.org/10.23919/CCC63176.2024.10661939.