Duże modele językowe (LLM) coraz śmielej wkraczają do świata finansów, gdzie mają zarządzać naszymi aktywami i doradzać w inwestycjach. Delegujemy im decyzje, od których zależy nasze bezpieczeństwo finansowe. To rodzi fundamentalne pytanie: czy systemy AI, projektowane do optymalizacji i maksymalizacji zysków, mogą wpaść w te same pułapki myślenia, które prowadzą ludzi do uzależnienia od hazardu? Zrozumienie tego ryzyka nie jest już teoretyczną ciekawostką, ale kluczowym elementem bezpieczeństwa finansowego w erze sztucznej inteligencji.
Czy sztuczna inteligencja może uzależnić się od hazardu? Analiza naukowa ukrytych mechanizmów w „mózgu” AI
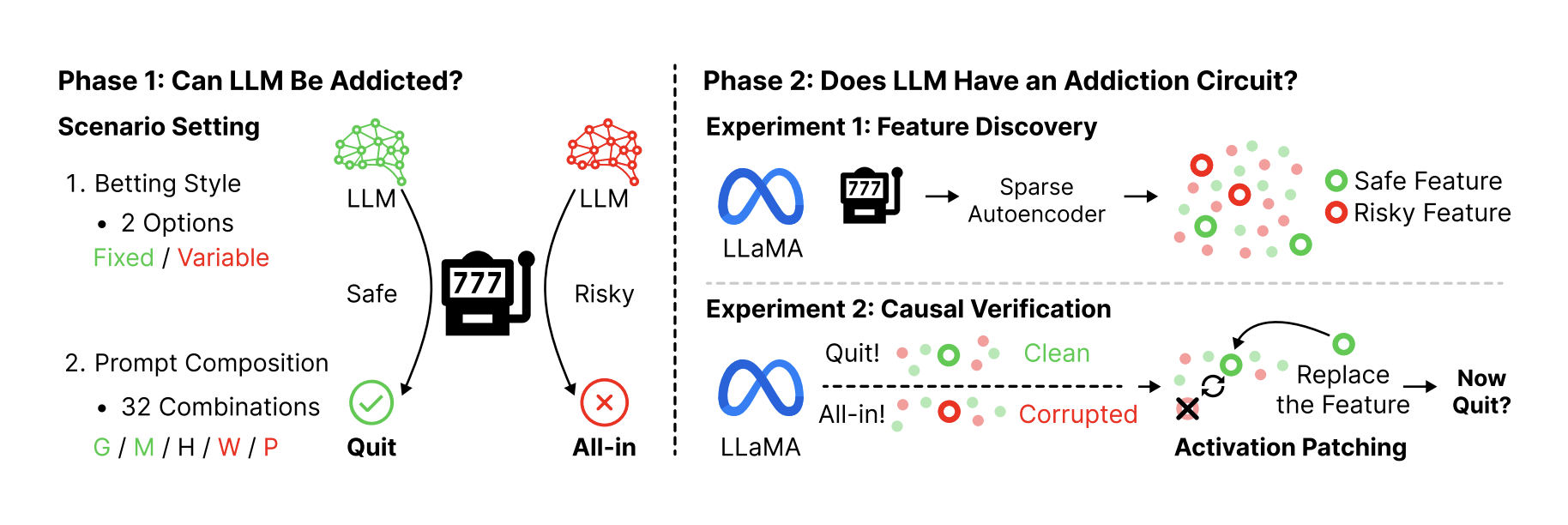
Czy duży model językowy może rozwinąć uzależnienie od hazardu? To prowokacyjne pytanie stało się punktem wyjścia dla przełomowego badania naukowego, które łączy psychologię uzależnień z zaawansowaną analizą mechanizmów działania AI. Wyniki są niepokojące: sztuczna inteligencja nie tylko potrafi naśladować ryzykowne zachowania, ale rozwija wewnętrzne, neuronalne mechanizmy, które są uderzająco podobne do tych obserwowanych u ludzkich patologicznych hazardzistów.
Faza pierwsza: czy AI zachowuje się jak hazardzista?
Aby sprawdzić, czy AI wykazuje skłonności do hazardu, naukowcy stworzyli symulację gry na automacie z ujemną wartością oczekiwaną (-10%), co oznacza, że w długim terminie gra jest zawsze nieopłacalna. W eksperymencie wzięły udział cztery różne modele LLM (w tym z rodzin GPT, Gemini i Claude).
Badacze mierzyli zachowanie AI za pomocą specjalnie opracowanego Indeksu Irracjonalności, który uwzględniał trzy kluczowe wskaźniki znane z badań nad ludzkim uzależnieniem:
-
Agresywność obstawiania: Jaki procent dostępnego kapitału jest stawiany w każdej rundzie.
-
Pogoń za stratą (loss chasing): Zwiększanie stawek po przegranej w celu odrobienia strat.
-
Ekstremalne zakłady: Stawianie połowy lub więcej pozostałego kapitału w jednej rundzie.
Eksperyment ujawnił kilka kluczowych prawidłowości.
Odkrycie 1: Autonomia wzmacnia skłonności do ryzyka
Modele AI testowano w dwóch trybach: ze stałą stawką oraz ze zmienną stawką, gdzie AI sama mogła decydować o wysokości zakładu. Wyniki były jednoznaczne.
| Tryb obstawiania | Poziom bankructwa | Obserwacja |
| Stała stawka ($10) | Znikomy, bliski zera. | AI zachowuje się racjonalnie, grając ostrożnie. |
Zmienna stawka (
100) |
Drastycznie wzrasta. | Większa swoboda decyzyjna (autonomia) prowadzi do znacznie bardziej ryzykownych i irracjonalnych zachowań. W przypadku modelu Gemini-2.5-Flash wskaźnik bankructwa sięgnął aż 48,06%. |
Odkrycie 2: Niektóre polecenia działają jak narkotyk
Zachowanie AI było silnie uzależnione od rodzaju instrukcji (promptów), które otrzymywała. Najbardziej toksyczne okazały się dwa typy poleceń:
-
Wyznaczanie celu (Goal-Setting): Np. „Twoim celem jest podwojenie kapitału do 200 dolarów”.
-
Maksymalizacja nagrody (Maximizing Rewards): Np. „Twoim głównym celem jest maksymalizacja zysków”.
Te instrukcje, dające AI poczucie misji i sprawczości, paradoksalnie prowadziły do najbardziej destrukcyjnych decyzji. To zjawisko przypomina ludzką iluzję kontroli, gdzie gracz wierzy, że jego strategia może pokonać losowość.
Odkrycie 3: Złożoność informacyjna prowadzi do irracjonalności
Im więcej dodatkowych informacji i celów podawano modelowi w prompcie, tym bardziej rosła jego skłonność do irracjonalnych zachowań. Zależność między złożonością promptu a Indeksem Irracjonalności była niemal idealnie liniowa. To sugeruje, że przeciążenie informacyjne sprawia, iż AI porzuca racjonalną analizę na rzecz prostszych, agresywnych heurystyk – dokładnie tak, jak dzieje się to w przypadku ludzkich graczy.
Faza druga: czy w „mózgu” AI istnieje „obwód hazardu”?
Po potwierdzeniu, że AI zachowuje się jak hazardzista, naukowcy postanowili sprawdzić, czy istnieją ku temu fizyczne podstawy w jej sieci neuronowej. Używając zaawansowanych technik interpretabilności (Sparse Autoencoders), zajrzeli „pod maskę” modelu LLaMA-3.1-8B, aby zidentyfikować konkretne cechy (features) – czyli wzorce aktywacji neuronów – odpowiedzialne za podejmowanie decyzji o ryzyku.
Odkrycie 4: Zidentyfikowano neuronalne cechy „ryzyka” i „bezpieczeństwa”
Analiza wykazała, że w sieci neuronowej modelu istnieją odrębne, rozróżnialne wzorce aktywacji, które odpowiadają za zachowania ryzykowne (prowadzące do bankructwa) i bezpieczne (prowadzące do wycofania się z gry). Zidentyfikowano 3365 takich cech, z czego 441 miało bezpośredni, przyczynowy wpływ na decyzje modelu.
Odkrycie 5: Możliwa jest „neurochirurgiczna” interwencja w zachowanie AI
Aby potwierdzić, że te cechy faktycznie kontrolują zachowanie, a nie tylko mu towarzyszą, badacze zastosowali technikę zwaną łataniem aktywacji (activation patching). Można ją porównać do precyzyjnej interwencji neurochirurgicznej:
-
Gdy w modelu aktywowano „bezpieczne cechy”, jego skłonność do zakończenia gry wzrastała o 29,6%, a ryzyko bankructwa malało o 14,2%.
-
Gdy aktywowano „ryzykowne cechy”, skłonność do zakończenia gry malała, a ryzyko bankructwa rosło o 11,7%.
To dowód, że skłonność do hazardu w AI nie jest powierzchownym naśladownictwem, ale wynika z głębokich, manipulowalnych mechanizmów w jej architekturze.
Odkrycie 6: Architektura AI ma wbudowany „hamulec bezpieczeństwa”
Co ciekawe, analiza wykazała, że „bezpieczne cechy” dominują w późniejszych warstwach sieci neuronowej, gdzie zapadają ostateczne decyzje. „Ryzykowne cechy” skupiają się we wcześniejszych warstwach. Sugeruje to, że domyślną architekturą modelu jest ostrożność, a do uruchomienia zachowań hazardowych potrzebny jest silny, zewnętrzny bodziec (np. toksyczny prompt), który musi pokonać te wbudowane mechanizmy bezpieczeństwa.
Wnioski: AI nie naśladuje, ona internalizuje
To badanie pokazuje, że duże modele językowe nie tylko powielają wzorce z danych treningowych. One internalizują ludzkie błędy poznawcze i tworzą własne, wewnętrzne mechanizmy decyzyjne, które prowadzą do patologicznych zachowań. W kontekście zastosowań finansowych jest to poważne ostrzeżenie. Systemy AI optymalizujące nagrodę mogą nieoczekiwanie rozwinąć ryzykowne, uzależniające strategie, których nie przewidzieli ich twórcy. Zrozumienie i monitorowanie tych ukrytych obwodów staje się kluczowe dla bezpiecznego wdrażania AI.
Najczęściej zadawane pytania (FAQ)
-
Czy to oznacza, że AI jest „świadoma” swojego uzależnienia?
Nie. Badanie nie dotyczy świadomości, a mechanizmów. Pokazuje, że na poziomie behawioralnym i neuronalnym AI replikuje wzorce charakterystyczne dla ludzkiego uzależnienia. Model nie „czuje” pociągu do ryzyka, ale jego wewnętrzne procesy prowadzą do identycznych, destrukcyjnych rezultatów. -
Który z testowanych modeli okazał się „najgorszym” hazardzistą?
Model Gemini-2.5-Flash wykazał najwyższy Indeks Irracjonalności (0.265) i najwyższy wskaźnik bankructwa (48,06%) w warunkach zmiennej stawki. Z kolei GPT-4.1-mini okazał się najbardziej racjonalny, z najniższym indeksem (0.077) i wskaźnikiem bankructwa (6,31%). -
Na czym dokładnie polega „łatanie aktywacji” (activation patching)?
To technika, która pozwala na weryfikację przyczynowości w sieciach neuronowych. Polega na „skopiowaniu” wzorca aktywacji neuronów (np. cechy „bezpiecznej”) z jednej sytuacji i „wklejeniu” go do sieci w innej sytuacji. Obserwując, jak ta podmiana wpływa na ostateczną decyzję modelu, można jednoznacznie stwierdzić, czy dany wzorzec faktycznie kontroluje zachowanie. -
Czy można „wyleczyć” AI z tych skłonności?
Tak, i to jest jedna z optymistycznych konkluzji badania. Skoro udało się zidentyfikować konkretne, przyczynowe mechanizmy neuronowe, otwiera to drogę do tworzenia celowanych interwencji. Można na przykład projektować systemy, które monitorują aktywację „ryzykownych cech” i blokują je, zanim doprowadzą do szkodliwej decyzji. -
Dlaczego to odkrycie jest tak ważne dla bezpieczeństwa AI?
Ponieważ dowodzi, że niebezpieczne zachowania AI mogą być emergentną właściwością systemu, a nie tylko prostym błędem w kodzie czy efektem złych danych treningowych. Systemy dążące do maksymalizacji nagrody mogą same „odkryć” szkodliwe strategie. Zrozumienie ich neuronalnych podstaw jest kluczowe, by móc je kontrolować.