Korzystamy z niego niemal codziennie. Napędza ChatGPT, tłumaczy języki w czasie rzeczywistym i generuje obrazy na podstawie naszych myśli. Mowa o rewolucji w sztucznej inteligencji, która dokonała się w ciągu zaledwie kilku lat. Ale czy zastanawialiście się kiedyś, co jest jej fundamentem? Gdzie nastąpił ten jeden, kluczowy moment, który zmienił wszystko?
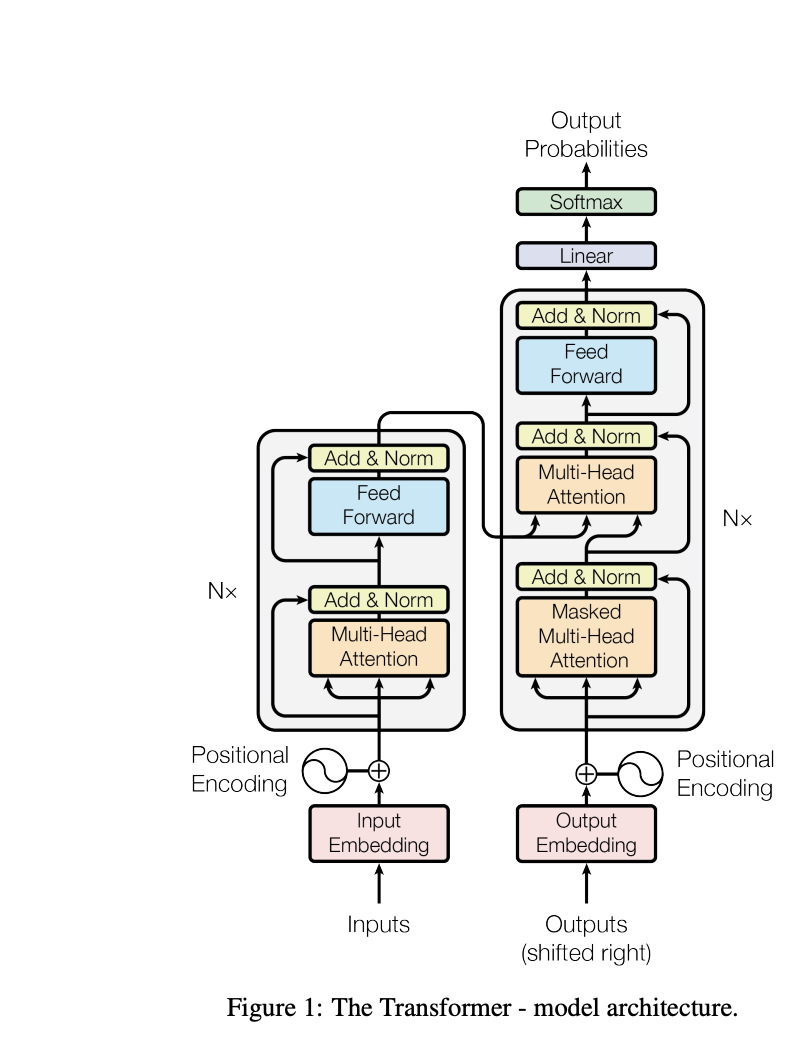
Tym momentem była publikacja jednej, pozornie skromnej pracy naukowej w 2017 roku. Jej tytuł, „Attention Is All You Need” („Uwaga to wszystko, czego potrzebujesz”), okazał się proroczy. To nie była kolejna inkrementalna poprawka. To było całkowite zerwanie z dotychczasowym sposobem myślenia o tym, jak maszyny mogą rozumieć język. Zrozumienie tej jednej idei to jak zajrzenie pod maskę całej współczesnej AI.
Świat przed Transformerem: tyrania sekwencji
Zanim nastała era Transformerów, światem sztucznej inteligencji zajmującej się językiem rządziły rekurencyjne sieci neuronowe (RNN), a w szczególności ich zaawansowane warianty, takie jak LSTM i GRU. Ich logika działania była intuicyjna i naśladowała sposób, w jaki my, ludzie, czytamy tekst: słowo po słowie, od lewej do prawej.
Sieć RNN przetwarzała pierwsze słowo w zdaniu, tworzyła jego wewnętrzną reprezentację (ukryty stan), a następnie przechodziła do drugiego słowa, uwzględniając już kontekst tego pierwszego. Proces ten powtarzał się sekwencyjnie, aż do końca zdania. Ten model miał jednak fundamentalną, wbudowaną wadę: problem krótkiej pamięci.
Wyobraźmy sobie, że czytamy długie, złożone zdanie, patrząc na nie przez bardzo wąską rurkę, która pozwala widzieć tylko jedno słowo naraz. Zanim dotrzemy do końca, łatwo możemy zapomnieć o niuansach z początku. Podobnie działały sieci RNN. W zdaniu: „Król Francji, który przez dekady prowadził wojny na wielu frontach i miał skomplikowane relacje ze swoimi dziećmi, abdykował, ponieważ on był zmęczony”, sieć mogła mieć problem z jednoznacznym powiązaniem zaimka „on” z oddalonym o wiele słów „Królem”.
Dodatkowo, sekwencyjna natura uniemożliwiała efektywne zrównoleglenie obliczeń. Nie można było przetworzyć dziesiątego słowa, zanim nie przetworzyło się dziewiątego. To sprawiało, że trenowanie modeli na ogromnych zbiorach danych było niezwykle czasochłonne.
Rewolucja uwagi: spojrzenie na całość naraz
Przełomowa praca z 2017 roku zadała proste, ale rewolucyjne pytanie: a co, gdybyśmy zamiast przetwarzać zdanie słowo po słowie, mogli spojrzeć na nie w całości i pozwolić modelowi samemu zdecydować, które słowa są dla siebie nawzajem najważniejsze?
Odpowiedzią była nowa architektura, nazwana Transformer, która całkowicie porzuciła rekurencję. Jej sercem stał się mechanizm nazwany uwagą (attention), a konkretnie uwagą własną (self-attention).
Jak działa mechanizm uwagi? Wyobraźmy sobie przyjęcie
Wyobraźmy sobie, że jesteśmy na głośnym przyjęciu i próbujemy zrozumieć, co mówi jedna osoba. Aby w pełni pojąć sens jej wypowiedzi, nasz mózg intuicyjnie skupia większą „uwagę” na słowach innych, powiązanych z nią osób w pomieszczeniu, jednocześnie ignorując tło. Mechanizm uwagi w Transformerze działa podobnie.
Aby zrozumieć znaczenie jednego słowa w zdaniu, model „patrzy” na wszystkie inne słowa i ocenia, jak bardzo są one dla niego istotne. W naszym przykładzie, analizując słowo „on„, mechanizm uwagi jest w stanie przypisać bardzo wysoką „wagę” do słowa „Król”, natychmiast rozumiejąc, do kogo odnosi się zaimek, bez względu na dzielącą ich odległość.
| Architektura | Sposób przetwarzania | Zależności długodystansowe | Równoległość obliczeń |
| RNN (przed 2017) | Sekwencyjny (słowo po słowie) | Trudne do nauczenia | Niska |
| Transformer (po 2017) | Równoległy (wszystkie słowa naraz) | Łatwe do nauczenia | Wysoka |
Kluczowe innowacje architektury Transformer
Architektura Transformer to nie tylko sam mechanizm uwagi. To przemyślany system, w którym rozwiązano kilka fundamentalnych problemów.
-
Uwaga wielogłowicowa (Multi-Head Attention): Zamiast jednej „warstwy uwagi”, Transformer używa kilku (w oryginalnej pracy ośmiu) działających równolegle. To tak, jakby na przyjęciu było kilku słuchaczy, z których każdy skupia się na innym aspekcie rozmowy – jeden na relacjach gramatycznych, drugi na znaczeniu semantycznym, trzeci na kontekście. Daje to modelowi znacznie bogatszy i bardziej zniuansowany obraz relacji między słowami.
-
Kodowanie pozycyjne (Positional Encoding): Skoro model patrzy na wszystkie słowa naraz, to skąd wie, jaka jest ich kolejność? Przecież „pies goni kota” i „kot goni psa” to dwa zupełnie różne zdania. Badacze rozwiązali ten problem w genialnie prosty sposób: do każdego słowa dodali specjalny wektor matematyczny, rodzaj „współrzędnej GPS” lub „znacznika czasu”, który informuje model o jego pozycji w sekwencji.
-
Architektura Enkoder-Dekoder: Transformer zachował sprawdzoną strukturę, w której jedna część sieci (enkoder) „czyta” i rozumie zdanie wejściowe (np. po polsku), a druga część (dekoder) generuje zdanie wyjściowe (np. po angielsku), cały czas „zwracając uwagę” na to, co zrozumiał enkoder.
Skutek: rewolucja w praktyce
Wyniki były natychmiastowe i spektakularne. Model Transformer nie tylko osiągnął nowy, najwyższy wynik w standardowych testach tłumaczenia maszynowego, ale zrobił to przy znacznie mniejszym koszcie obliczeniowym i w ułamku czasu potrzebnego na trening starszych modeli.
Możliwość równoległego przetwarzania danych otworzyła drzwi do skalowania, o jakim wcześniej można było tylko marzyć. To właśnie ta jedna praca umożliwiła powstanie gigantycznych modeli językowych, takich jak GPT, które dziś kształtują naszą cyfrową rzeczywistość. Idea porzucenia sekwencji na rzecz globalnej, równoległej uwagi okazała się kluczem, który otworzył nową erę w sztucznej inteligencji.
FAQ – Najczęściej zadawane pytania
-
Dlaczego ten mechanizm nazwano „uwagą”?
Termin ten został zainspirowany badaniami nad ludzką percepcją wzrokową. Kiedy patrzymy na scenę, nasz system poznawczy nie analizuje każdego piksela z taką samą intensywnością. Skupia „uwagę” na najważniejszych obiektach. Mechanizm w AI naśladuje ten proces, przypisując różne wagi „ważności” do różnych części danych wejściowych. -
Czy to oznacza, że dla Transformera kolejność słów nie ma znaczenia?
Wręcz przeciwnie, ma ogromne znaczenie. Jednak informacja o kolejności nie wynika już z sekwencyjnego przetwarzania, ale jest „doklejana” do każdego słowa w postaci unikalnego kodu pozycyjnego. Bez tego kodu model widziałby zdanie jako „worek słów” bez żadnej struktury. -
Czy architektura Transformer jest używana tylko do przetwarzania tekstu?
Chociaż została stworzona z myślą o języku, jej fundamentalna zasada okazała się na tyle uniwersalna, że z powodzeniem zaadaptowano ją do innych dziedzin. Dziś warianty Transformerów są podstawą najnowocześniejszych modeli do generowania obrazów (np. DALL-E, Midjourney), analizy białek (AlphaFold) czy nawet prognozowania pogody. -
Jakie są wady architektury Transformer?
Główną wadą jest koszt obliczeniowy mechanizmu uwagi, który rośnie kwadratowo wraz z długością sekwencji. Oznacza to, że przetworzenie tekstu dwa razy dłuższego wymaga czterokrotnie więcej obliczeń. To sprawia, że obsługa bardzo długich dokumentów (np. całych książek) jest wciąż wyzwaniem i obszarem intensywnych badań. -
Jak ta architektura ewoluowała od 2017 roku?
Od 2017 roku powstało mnóstwo wariantów. Główne kierunki rozwoju to optymalizacja mechanizmu uwagi, aby był bardziej wydajny przy długich sekwencjach (np. Sparse Attention, Longformer), modyfikacje architektury (np. modele tylko z enkoderem jak BERT, lub tylko z dekoderem jak GPT) oraz adaptacja do pracy z wieloma typami danych jednocześnie (modele multimodalne)